Top1. Overall strategy
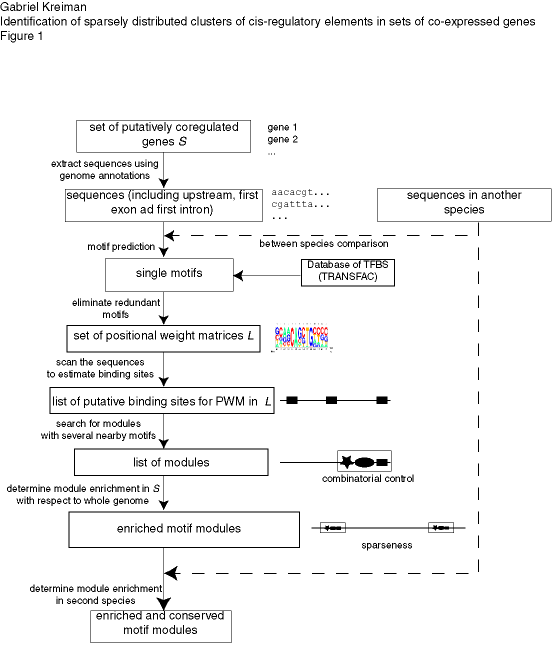
Given a set of potentially co-regulated genes, our algorithm searches for common sequence patterns that are unexpected by chance (see Figure 1 for a schematic description of the algorithm). The search is based on locating co-occurrences of putative binding sites for transcription factors within short segments of DNA. We tested the algorithm on artificial sequences with implanted modules, on random sets of genes (negative control) and in three experimentally validated systems encompassing a wide range of sequence characteristics: the CLB2 cluster in yeasts (Spellman et al., 1998), a set of genes involved in pattern formation in flies (Berman et al., 2002) and a set of genes co-expressed in the human skeletal muscle (Wasserman and Fickett, 1998). All the code is available upon request.
Figure caption: Schematic description of our approach to find cis elements in eukaryotes based on combinatorial usage of transcription factors and sparseness of the regulatory modules. The approach involves searching for co-occurrences of motifs that are highly enriched in the set of potentially co-regulated genes (S) with respect to the set of all genes in the corresponding genome. The upstream region, first exon and first intron are retrieved for each gene in S. Non-conserved sequences can be masked to reduce the level of noise. A list of individual PWMs (L) is created by (i) searching for new motifs (using the motif finding programs alignACE, MEME and MotifSampler) on the upstream, first exon and first intron sequences of the genes in S and independently (ii) from motifs from the TRANSFAC database. Modules are defined by clusters of motifs within small DNA segments and enrichment is evaluated by comparing the occurrences of the module in the set S against all the genes in the genome (see Methods). The boxes indicate the output of the previous step. The arrows indicate the processs(es) involved in each step.