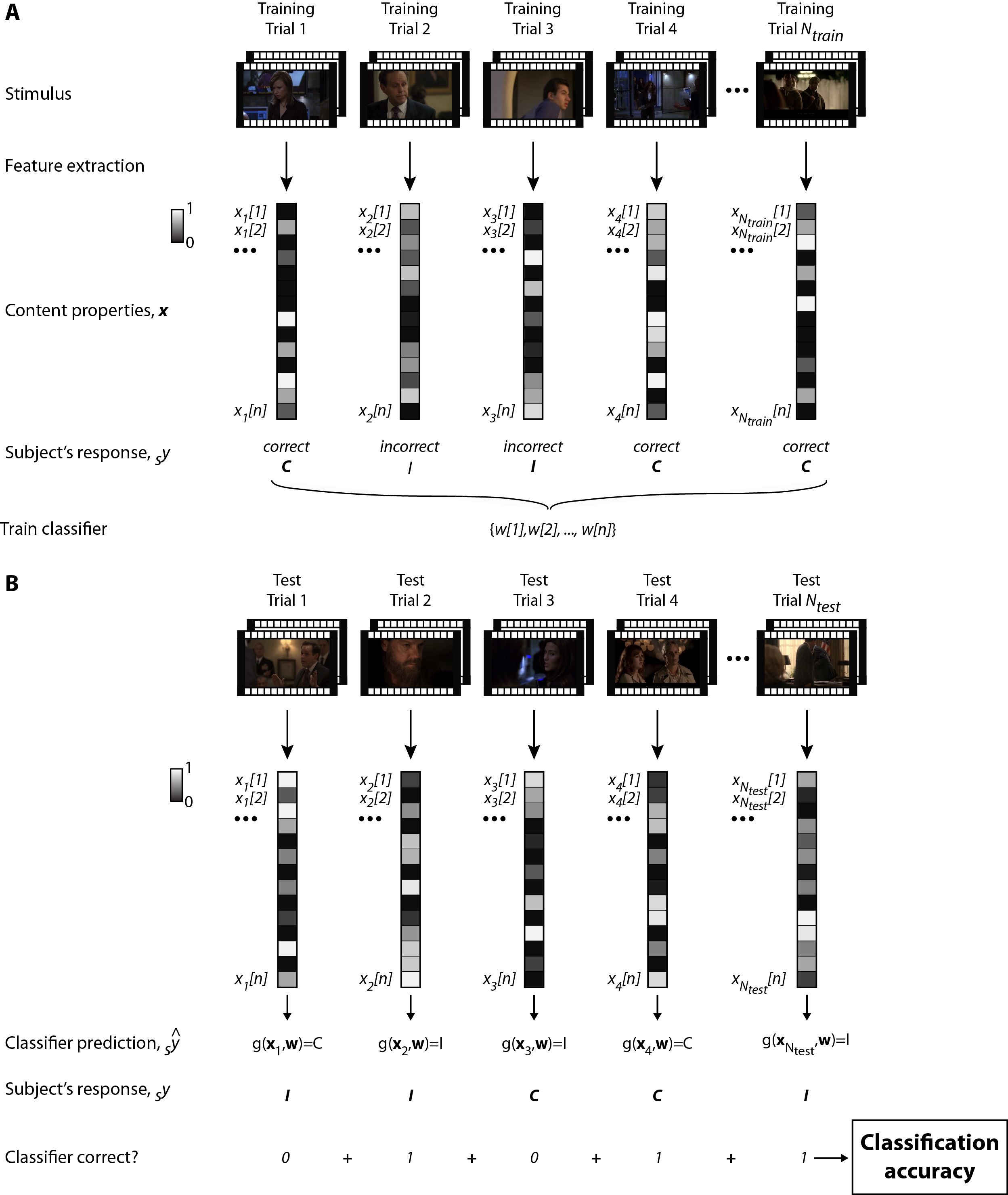
Figure W2: Schematic illustration of the machine learning approach to predict memorability in single trials (Original version of Figure 6). Due to copyright issues, we had to replace the movie frames in the figure by artistic renderings. Here we show the original version of the figure and the actual frames that the subjects saw. The data were randomly divided into a training set with Ntrain trials (A) and a test set with Ntest trials (B). In each trial, a shot was presented and the subject responded correctly (C) or incorrectly (I). We extracted the set of n content properties x[1], …, x[n] for the shot including low-level visual/auditory properties, high-level properties, emotional properties (Methods; Tables S2-S3). The same approach is followed for single frames. A support-vector machine with a linear kernel was trained to learn the map between the content properties x and the correct/incorrect labels y, resulting in a set of weights w[1], …, w[n]. During testing (B), we used a different set of shots that did not overlap with the ones in the training set and used the weights w to predict whether the subject was correct or not. By comparing the machine learning predictions with the actual subject responses, we determine whether the classifier was correct or not in each trial and compute the overall classification accuracy (where 50% is chance and 100% is perfect performance). This classification accuracy is shown in Figures 7, S9 and S10)..